Requests
Fetching remote data, then parsing or querying it
The web is all about fetching data from remote sources. Fortunately, SEL provides an event type to make these requests that support common data formats.
Request
A Request fetches data from a remote location (URL).
In the Pipeline View, you can click "Add New" to add a Request event that looks like this:
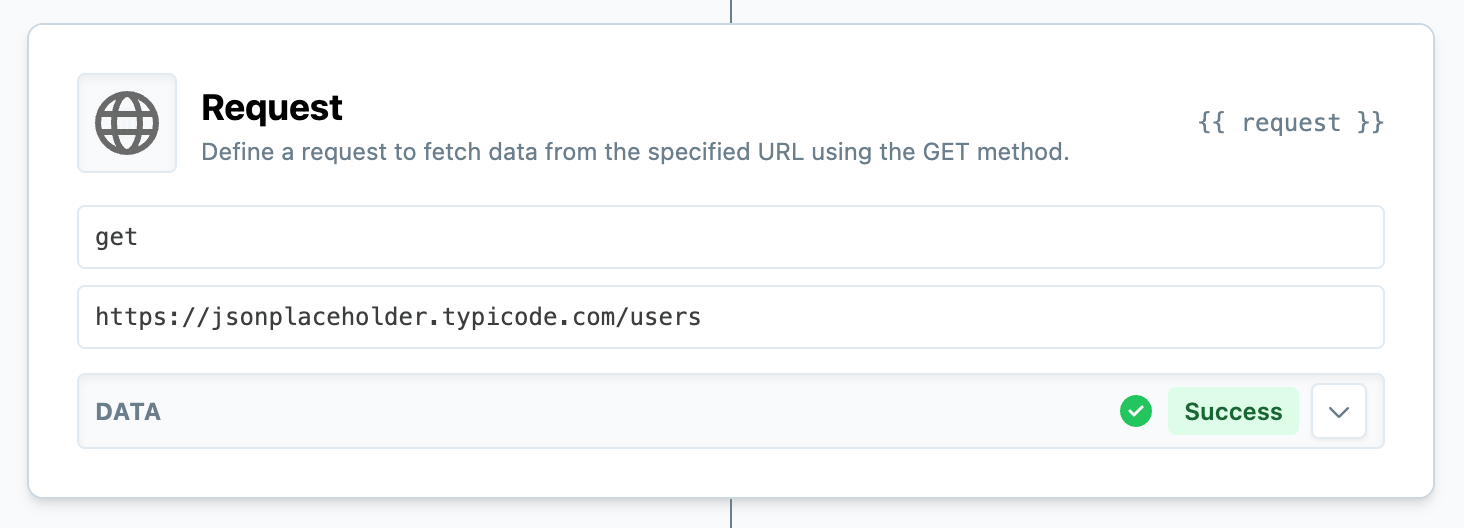
A basic example request in the pipeline view.
We can also pass common arguments params, cookies, json, and headers to Request. Let's look at an example in context:
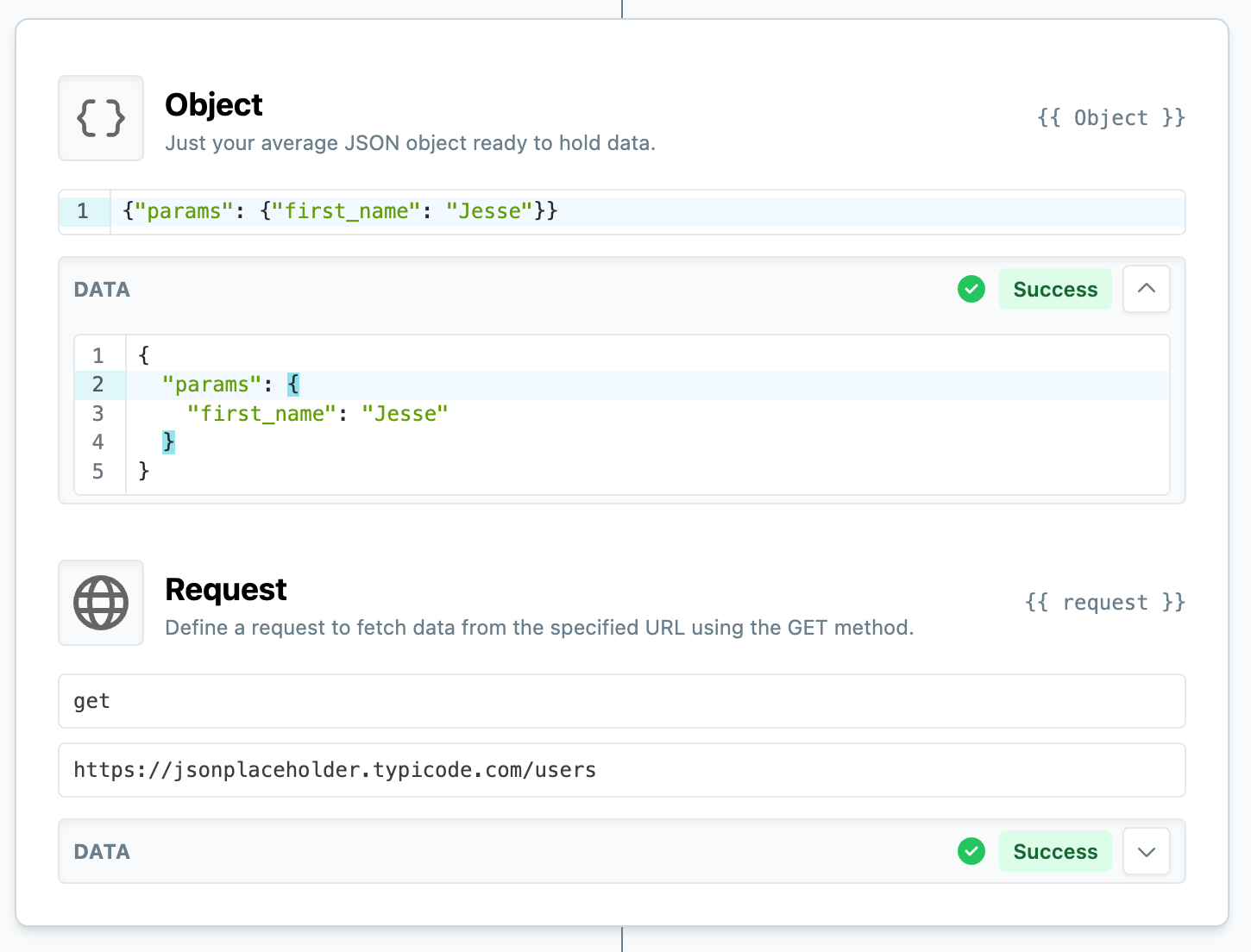
Passing some configuration options to a request.
In this example, we create an Object to store the parameters that need to be passed to the Request.
Authenticated Requests
Often, you'll be asked to provide an API key or token when making a request to an external site or service. To do so, we can send a configuration object to the Request, like so:
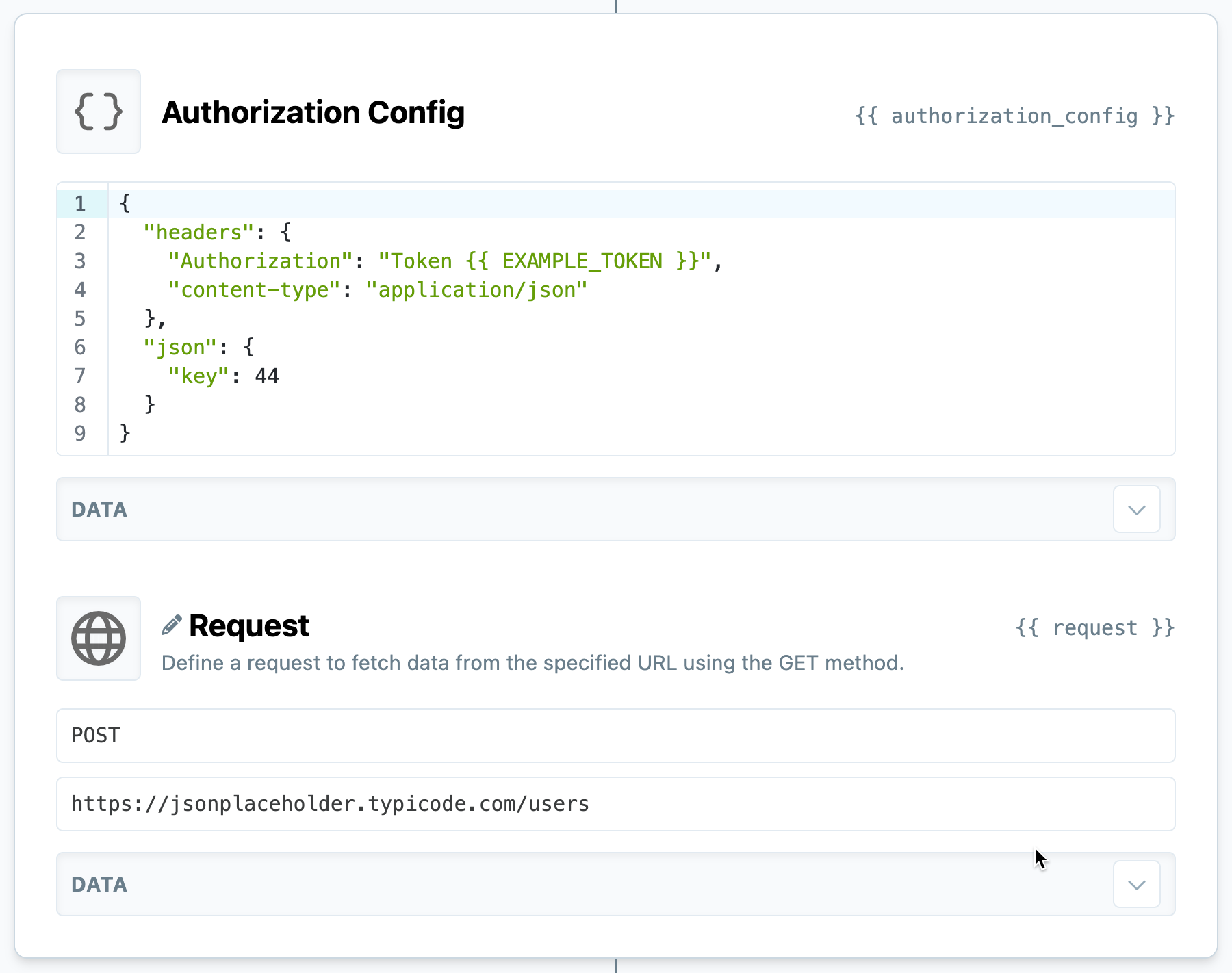
Making an authenticated request to an external resource.
The exact shape of this authorization object will vary by service. You should look for an example in their API documentation.
API key security
Many endpoints and API's require the use of keys, usernames, passwords, and/or tokens, in order to authenticate. To use these in SEL while keeping them secure, you should place them in your account Vault. This allows you to refer to them in your SEL code using liquid syntax, e.g.
{{ EXAMPLE_TOKEN }}instead of inserting them as text. This keeps your secrets encrypted and out of your model code.
Screenshots
If you'd like to take a screenshot of a webpage, use img as the method:
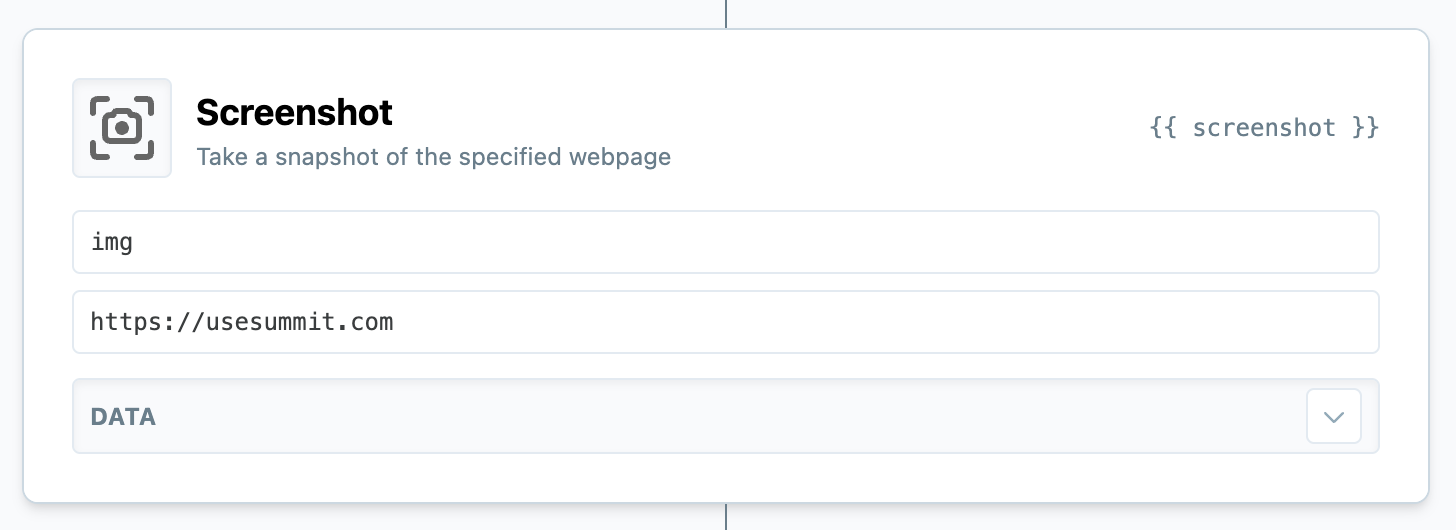
This will attempt to return a base64-encoded image/png of the full contents of the web page specified by the second argument. Screenshots over 10MB will fail.
These images can be passed to directly to a Persistent Storage event for uploading, or a vision-aware AI like gpt-4o.
Request configuration options
A full list of options that can be sent to Request using a preceding Object. The Option in the table is the object key.
| Option | Purpose | Value | Default |
|---|---|---|---|
params | Querystring arguments. | A dictionary of key-value pairs. | None |
headers | Request headers. | A dictionary of key-value pairs. | None |
json | JSON body arguments. | A dictionary of key-value pairs. | None |
cookies | Cookies to include. | A dictionary of key-value pairs. | None |
sleep | Place a pause before making the request. | Any number or decimal (seconds) | 0 |
timeout | Tell the request how long to wait before considering the request a failure. | Any number of seconds. | 10 |
cache_duration | Choose how long you'd like Summit to cache the response. Useful for higher performance when the underlying data doesn't change very often, or when you want to limit your unique requests to the endpoint. | Any number of seconds. | 60 |
scrape | A set of rules to extract HTML nodes (DOM entities) from a web page. | A dictionary of key-value pairs. | None |
Proxy Requests (Oauth)
Some services require a more complex series of requests in order to authenticate and connect, sometimes referred to as a handshake, or "oauth". For these, such as HubSpot, Pipedrive, Salesforce, and Airtable, Summit provides 1-click integrations that you can then use throughout your model code.
The full list (which may change since the publishing of this documentation) can be found on your Data Sources screen.

Using a secure connection
Once connected, you can choose from one of our pre-built plugins using the + button in the pipeline view:
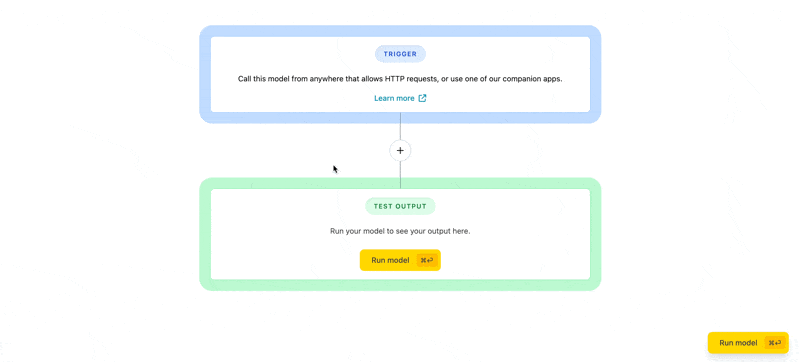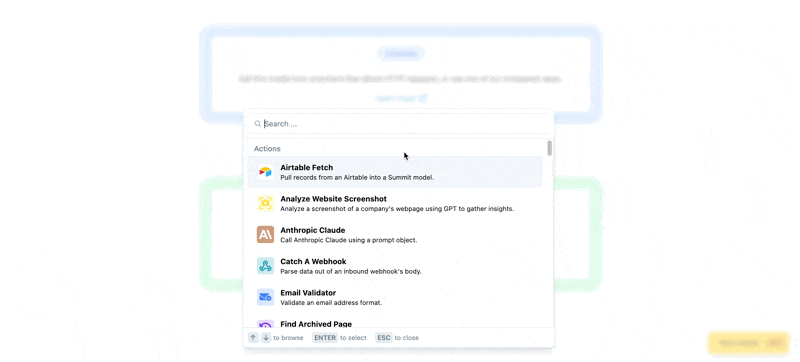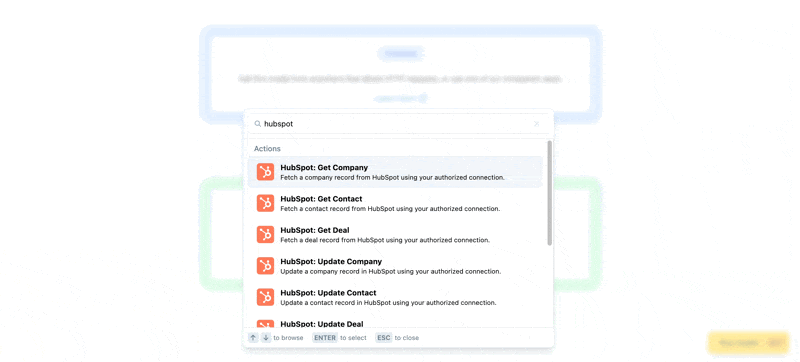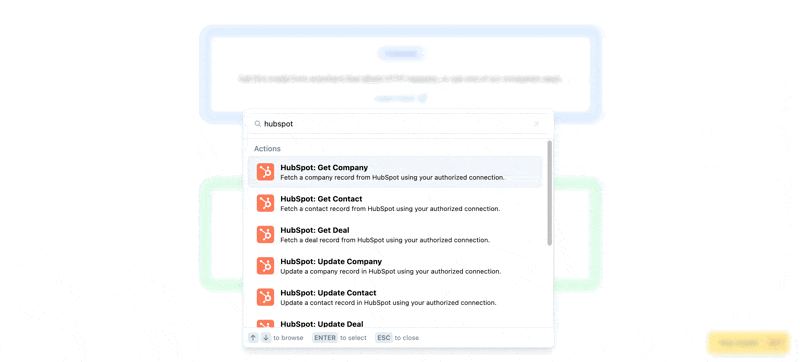
Or for more control, you can create a new Proxy event using the canvas view.
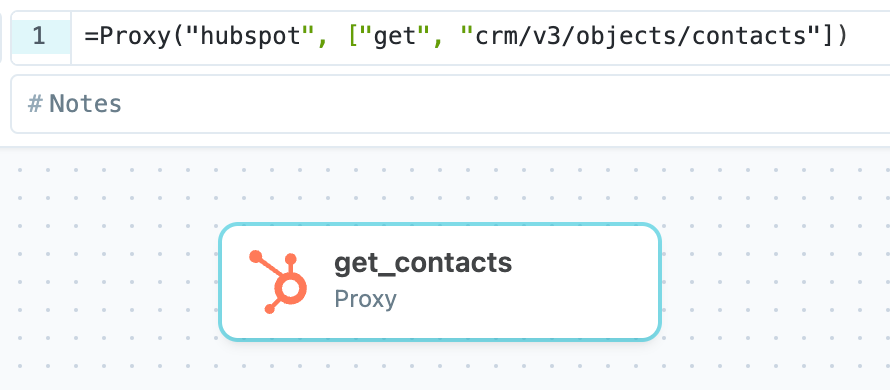
The first argument, ex. "hubspot", is the name of the service, and the second and third arguments are the request method and API endpoint to hit.
Example
A secure request to HubSpot will look like this. Notice the use of an object to define the data payload, which in this case specifies the attributes we want to retrieve off of a specific contact (record_id).
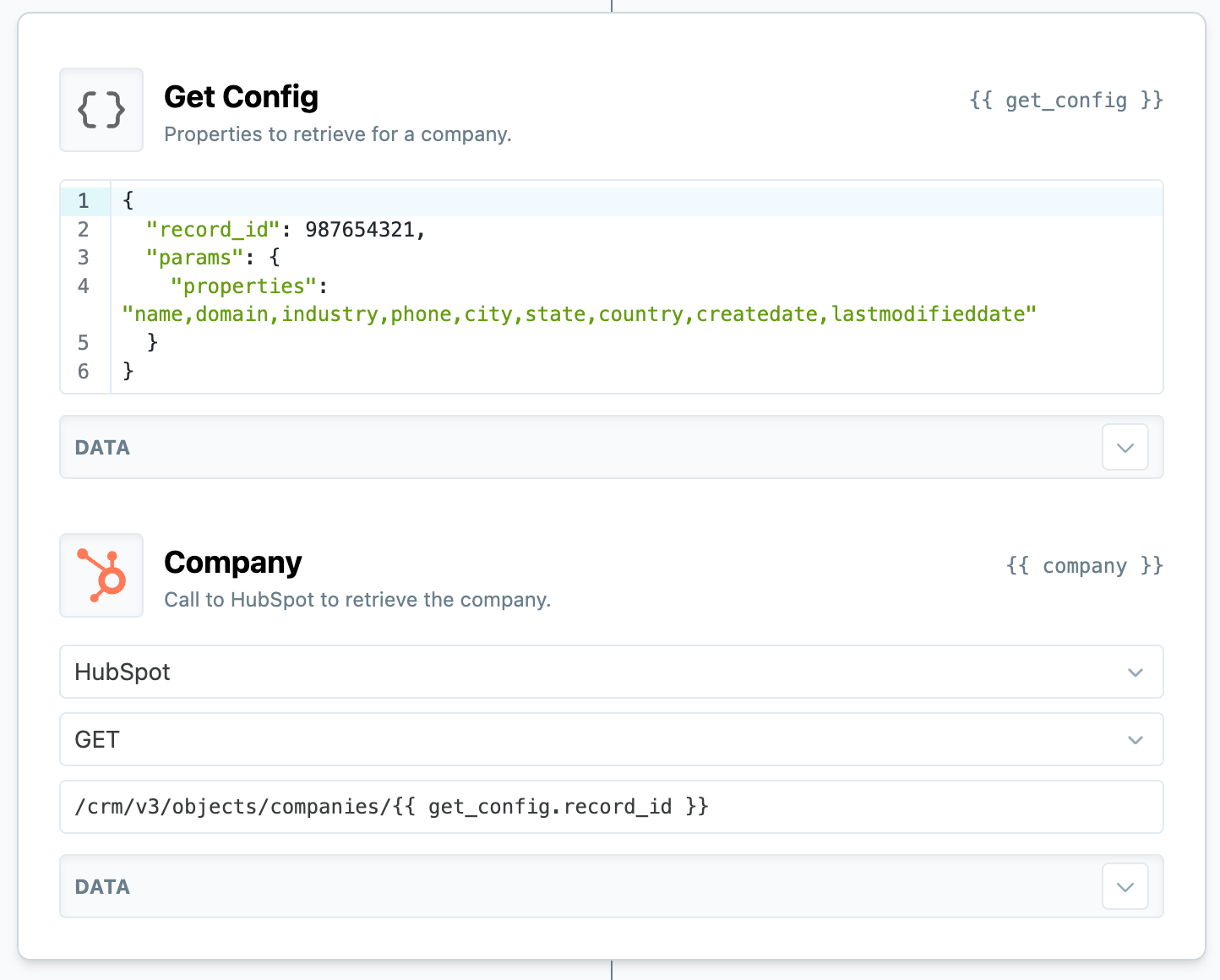
The second two arguments define the method and API endpoint of the remote service you'd like to access. You should always omit the protocol (ex. https://) and host (ex. api.hubspot.com).
Since Summit already possess an authenticated connection, you do not need to provide this proxy event with an Authentication header. However, you almost always still need to use an upstream Object event to populate other request arguments, such as the json body or query parameters.
Parser
The easiest way to use the results of your request is referencing the event using liquid syntax in another event, like so:
{{ my_request.data_results[0] }}
Sometimes, however, the output of a request might be a rather complex structure of JSON. If you want to quickly extract a certain set of nodes from a complex JSON response, you should use a Parser event.
These events take a JSONPath argument that defines a search to retrieve the value you want from the response data, like so:
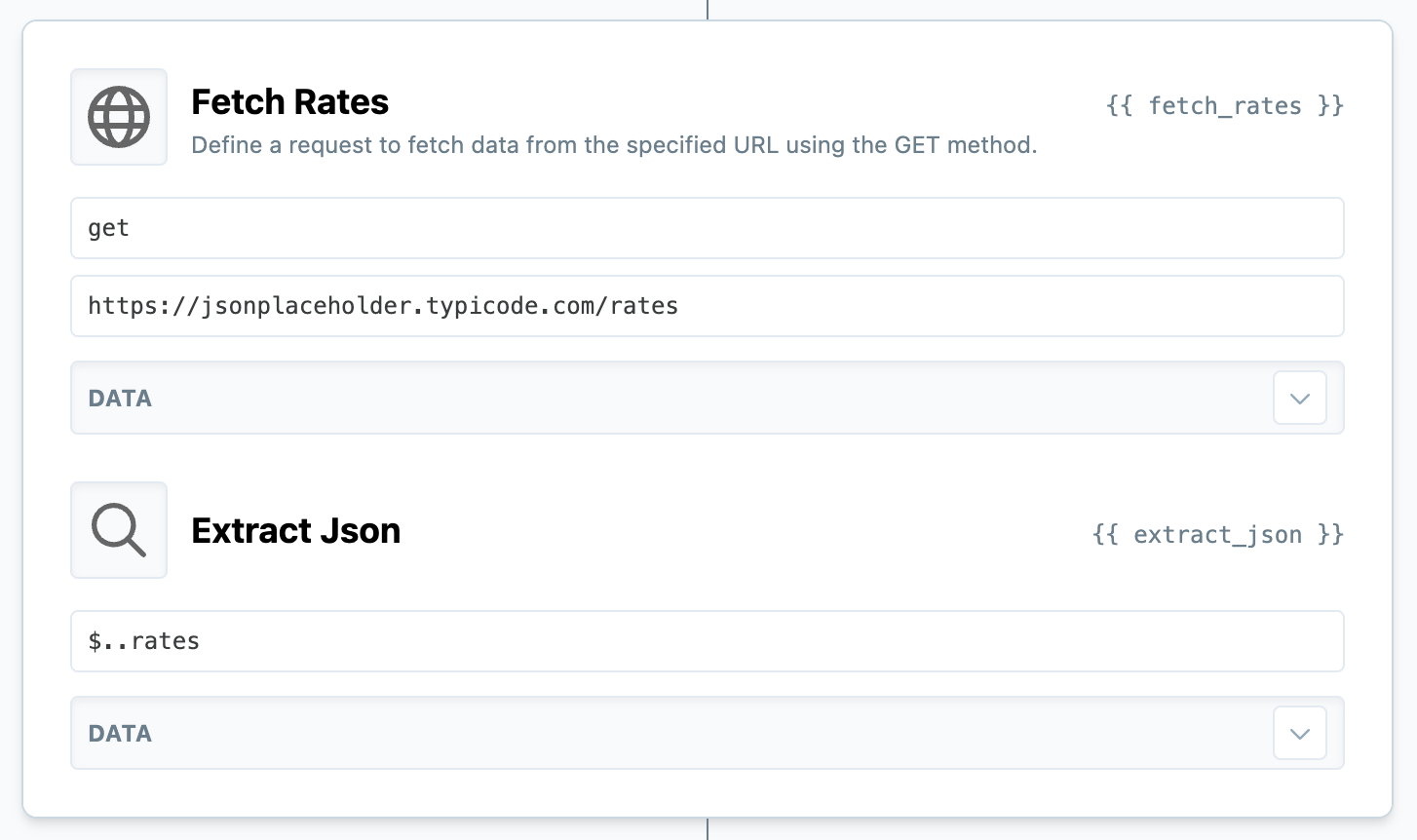
Using a Parser to find all of the "rates" nodes in this JSON response.
The parser event itself will extract and pass along the values it finds using your expression as a list of values.
JSONPath resources
SEL uses the
jsonpath-ngPython module to search your data using this expression. You can read more about this module here: https://pypi.org/project/jsonpath-ng/Writing a complex JSONPath expression can be challenging. In addition to asking ChatGPT, this site is a handy way to test a JSONPath expression against a JSON object: https://jsonpath.com/.
Scraping
Requests should be used to perform individual requests to specific endpoints or API's.
To perform more complex actions, such as web-scraping, you should use our Browser event.
Tables & Queries
Our data tables and queries docs have moved.
Check out Tables & Queries!
Updated about 1 month ago