Browser
A browser to navigate the web, ideal for scraping.
When you need to navigate or scrape the web, you should use a Browser event:
=Browser()
This will create a headless browser, specifically Chrome (Chromium) that can be fed a list of actions like going to pages, clicking buttons, scrolling, taking screenshots, listening for data, and even performing drag-and-drop.
To perform these actions, you need to send an Object to the browser event. This object contains a list of actions to perform, like so:
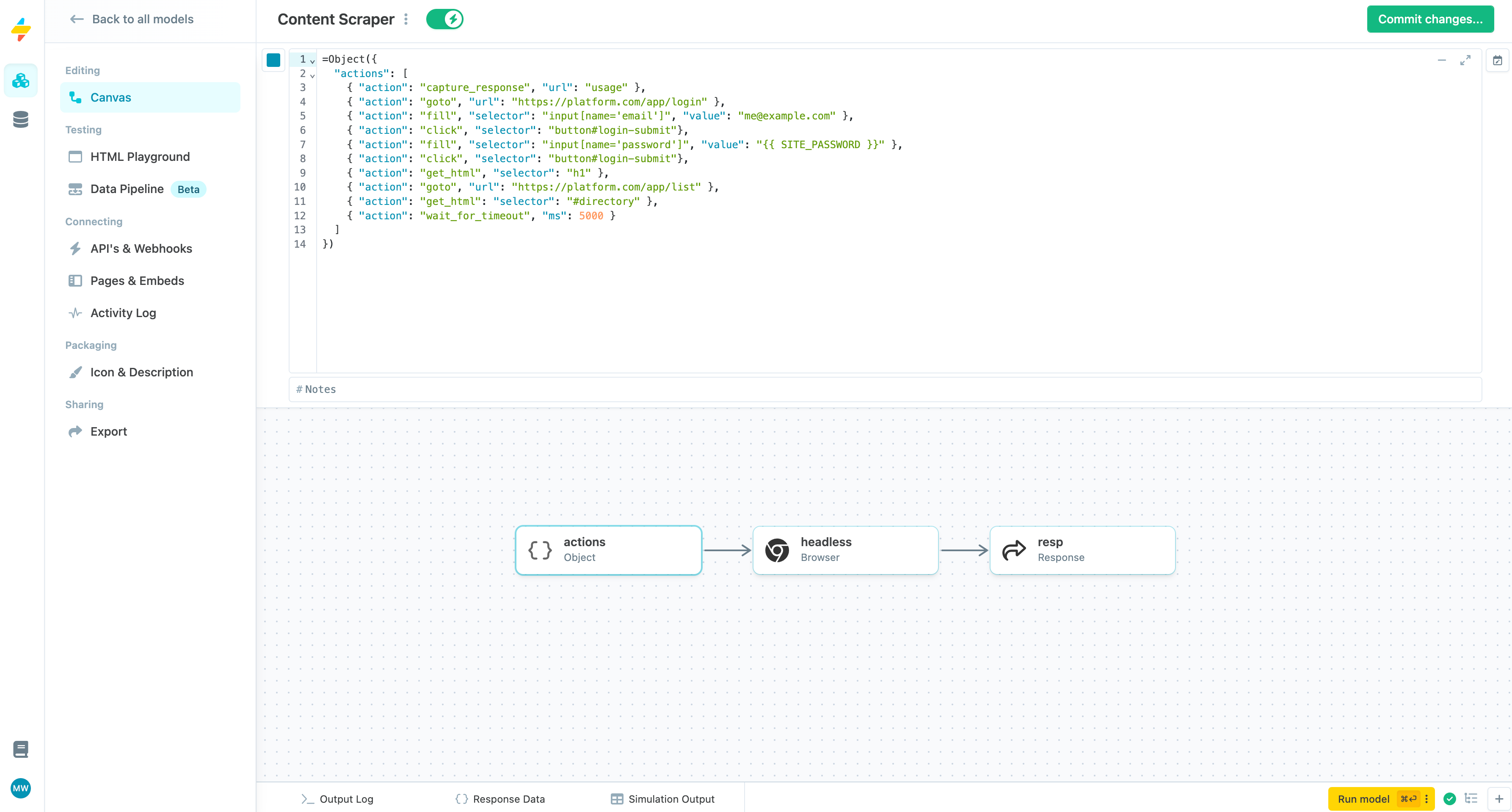
Defining actions for a headless browser.
The JSON data gathered by the capture_response action and the HTML fetched by the get_html action will be stored in the headless (Browser) event, and available in downstream blocks by referencing the {{ headless }} variable.
A full list of available browser actions follows.
Browser actions
| Action | Description | Example |
|---|---|---|
goto | Navigates to a specified URL. | { "action": "goto", "url": "https://example.com" } |
capture_response | Captures network responses for a specific URL. | { "action": "capture_response", "url": "https://example.com/api/data" } |
get_html | Retrieves HTML content of a specific element or entire page. | { "action": "get_html", "selector": "#content", "key": "pageContent" } |
click | Clicks an element identified by a selector. | { "action": "click", "selector": "#submit-button" } |
dblclick | Double-clicks an element. | { "action": "dblclick", "selector": "#item" } |
hover | Hovers over an element. | { "action": "hover", "selector": "#menu-item" } |
check | Checks a checkbox element. | { "action": "check", "selector": "#agree-checkbox" } |
uncheck | Unchecks a checkbox element. | { "action": "uncheck", "selector": "#subscribe-checkbox" } |
fill | Fills an input field with a specified value. | { "action": "fill", "selector": "#username", "value": "myUser" } |
select_option | Selects an option from a dropdown or list. | { "action": "select_option", "selector": "#country-select", "value": "US" } |
focus | Focuses on a specific element. | { "action": "focus", "selector": "#email" } |
scroll_to_element | Scrolls the page until the element is in view. | { "action": "scroll_to_element", "selector": "#footer" } |
press_sequentially | Presses a sequence of keys on a selected element. | { "action": "press_sequentially", "selector": "#search", "keys": ["A", "B", "C"] } |
wait_for_timeout | Waits for a specified number of milliseconds before continuing. | { "action": "wait_for_timeout", "ms": 3000 } |
wait_for_selector | Waits for an element to appear before proceeding. | { "action": "wait_for_selector", "selector": "#loading-indicator" } |
wait_for_response | Waits for a network response from a specific URL. | { "action": "wait_for_response", "url": "https://example.com/api" } |
handle_dialog | Handles a dialog popup, accepting or dismissing it, with optional input text. | { "action": "handle_dialog", "dialog_action": "accept", "input_text": "Yes" } |
assert | Asserts that an element’s property (e.g., textContent) matches the expected value. | { "action": "assert", "selector": "#welcome-text", "expected": "Welcome", "property": "textContent" } |
screenshot | Takes a screenshot of the page or a specific element and stores it as base64. | { "action": "screenshot", "path": "capture.png", "selector": "#content" } |
scroll_to | Scrolls the page to specified coordinates (x, y). | { "action": "scroll_to", "x": 0, "y": 500 } |
evaluate | Executes a JavaScript expression on the page. | { "action": "evaluate", "expression": "document.title" } |
drag_and_drop | Drags an element from one location to another. | { "action": "drag_and_drop", "source": "#drag-source", "target": "#drop-target" } |
Additional resources
The above actions and the
Browserevent are powered by a popular Python library called Playwright. A quick web or YouTube search should provide many additional examples and tutorials of how to chain these actions together. You may also want to try copy-pasting the above table into GPT and asking it to help you author your own scraping recipe.
Updated about 1 month ago